
Nicholas Joint, Tony Kidd, William Nixon, Michael Roberts
This article considers changes over the last two years in the electronic journal service provided by Glasgow and Strathclyde University Libraries, following an earlier article in Serials. We discuss differences between browsing for e-journals on the web, and searching for them on the opac, and examine the ways that each library has tried to combine these different access modes. Following a discussion of possible co-operation between the two libraries, we briefly explore the move towards the 'one-stop shop' and the potential contribution of aggregators.
Nicholas Joint is Subject Librarian at Strathclyde University Library (n.c.joint@strath.ac.uk), 101 St James Road, Glasgow G4 0NS; Tony Kidd is Head of Serials at Glasgow University Library (t.kidd@lib.gla.ac.uk), Hillhead Street, Glasgow G12 8QE; William Nixon is Assistant Head of IT Services at Glasgow University Library (w.nixon@lib.gla.ac.uk); Michael Roberts is Head of Serials at Strathclyde University Library (m.roberts@strath.ac.uk).
Both Glasgow University and Strathclyde University Libraries introduced electronic journal service web pages in the academic session 1996-1997.1 The aim was to promote e-journals as a user-friendly networked medium within a local electronic library service from which the inexperienced user could expect guidance and support. How have these two services fared in the intervening period?
Initially, both libraries maintained a web server route and an opac route to an e-journal web page. This is not an untypical way to provide access- writing of e-journal promotion at Loughborough University Library, Hazel Woodward describes:
"a series of Web pages…providing an A-Z listing of all e-journals. We are also working on providing access to e-journals from the Library's Web OPAC." 2 (p 233)
And in both Glasgow and Strathclyde there was an expectation that this commitment to maintaining two parallel sets of information and access points into a single electronic service would be rationalised at some point in the future.
Thus, a single opac path appeared to be the favoured option, with the web server records being removed entirely. Alternatively, the library web pages could have been used as the main access route to electronic journal services while the opac concentrated on listing hardcopy holdings. But in this scenario a hyperlink both ways between opac and web pages is needed to bring together information about a journal's availability in both formats; or the introduction of Z39.50 broadcast searching would be essential to enable the user to search opac and web server simultaneously, creating a composite result from two sources, opac and web pages.
On the face of it, the latter option seemed clumsy and less attractive - if the opac was the established way of tracing print journal information, it should remain the single significant way of locating journal information, whether the journal be in electronic format or not. And the opac-based approach has the bonus of a unified rather than a split approach. A user friendly information system should not confront the user with the confusing choice of two different listings - why look in two places when you could more easily look in one?
Interestingly, however, both libraries have maintained a dual access policy to a greater or lesser extent. This is in spite of the extra workload involved in maintaining such a belt and braces approach. How can this be justified?
The crucial reason for maintaining two access paths to our e-journal records at both libraries was the actual pattern of use displayed by readers in accessing electronic journals. For example, at Strathclyde the number of accesses to e-journal services via web pages or opac has always been counted by a statistics package. And according to these statistics, the most heavily used access route was the web e-journal record, not the opac record, by a number of three web record accesses for each opac access. Clearly, our web listings of e-journal titles are offering something that the opac routes do not.
At Glasgow, there are no statistics available for accesses of individual opac pages, but accesses to the web e-journal pages have been running at up to 20,000 per month - that covers all Glasgow e-journal pages, and does not mean of course that 20,000 articles are being viewed or downloaded each month. Nevertheless, it is very hard to believe that direct interrogation of the opac is anything like as popular. Queries from users at Glasgow also confirm that the most common starting point for those who wish to use e-journals is the web, rather than opac.
The most obvious difference between a set of e-journal web pages and e-journal opac records is that the web pages are browsable, while an opac, by definition, is for searching. Is a browsable set of e-journal web pages therefore the more user friendly route?
A recent article about the eLib SuperJournal project discussed its preliminary usage results, and analyses these issues of searchability and browsability:
"Despite provision of a number of types of search engines in the SuperJournal Application, the actual usage of any of these engines is low. In contrast there are high levels of browsing by all users." 3 (pp 120-121)
Of course, this discussion of search engines for e-journals is not the same facility as an opac search, and the browsing described is from article to article rather than through web pages listing e-journals by title and by subject (the style of web pages offered at both Glasgow and Strathclyde). The author makes the additional qualification, "It really needs long term repeat usage for a confident assessment of actual behaviour" (p 120).
Nevertheless, such research is sufficient to make the practitioner librarian, keen on maximising use levels of a still new type of service, reluctant to abandon the browsable web e-journal title and subject listing for a search-only opac route. If the SuperJournal project shows evidence of user reluctance to search for e-journals in a web-based environment, how much less effective is e-journal promotion when records describing them are hidden in a large university library opac among a much greater number of records describing dissimilar, hard copy resources? And as recent research has argued, effective e-journal promotion from academic libraries is an essential part in the medium achieving its full potential.4 Indeed, the preference for browsing may be a reflection of the relative novelty, even after a number of years, of e-journals.
Glasgow University Library was fortunate in having adopted a web-based
approach to the presentation of its portfolio of information services which was
in harmony with the need to balance the benefits of web browsability and opac
searchability in e-journal record provision (a useful discussion of the search
and browse tactics discussed in this article is put forward by Bates 5).
Figure 1. Glasgow University Library opening MERLIN screen.
The MERLIN (http://merlin.lib.gla.ac.uk/) approach (see Figure 1) aims to provide a seamless gateway to traditional library information resources (monographs and serials) and their direct electronic equivalents (e-journals and electronic books) while embedding this webpac search facility within a larger browsable web environment which lists both electronic resources unique to the internet (internet gateways and search engines, useful web sites, and other networked non-book, non-journal services), and recognisably equivalent electronic versions of books and journals. The MERLIN webpac is searchable, while the MERLIN web pages are browsable.
Obviously, there is a duplication of access routes for e-journals in this approach. But any sense of confusion or unnecessary overlap is avoided in two ways. Firstly, the single building block on which the edifice is constructed is the webpac record, which is where both the web-based title alphabetical and subject lists lead to - bibliographic information is kept in one place in a single bibliographic record. Glasgow changed to this system in the summer of 1998, having previously had separate web e-journal pseudo-catalogue records, originally because the catalogue, in its telnet, pre-web, days, could not support the use of the 856 MARC tag for direct linking to electronic resources. Secondly, the sense of a single, seamless information system is generated by the common graphic design used on every web page in MERLIN, be it a browsable web page or searchable webpac record (Figures 2 and 3).
![Figure 2. Glasgow University Library e-journal subject list [browsable].](Image5.gif)
Figure 2. Glasgow University Library e-journal subject list [browsable].
![Figure 3. Glasgow University Library webpac entry [searchable].](Image6.gif)
Figure 3. Glasgow University Library webpac entry [searchable].
The header and footer design common to each page of MERLIN is thus not simply the useful navigation and orientation device found in many higher education and commercial web sites. Its specific information retrieval function is to create the feeling of a seamless, single information system where the crossover between different parts of the system (e.g. opac and web pages) is hidden. In reality, the user is employing quite different information retrieval tactics in different parts of the system, but the choice of a different tactic is made intuitively, and is appropriate to the type of information sought.
In contrast to Glasgow University Library, within the Andersonian Library, the largest campus library in the Strathclyde University system, the opac is used as the main interface to all information resources, be they traditional printed monographs and serials or electronic journals. So, whereas in Glasgow the would-be user of an e-journal will approach a workstation and see the MERLIN web interface, within which the opac is an option, at Strathclyde the user will consult a pc with the Horizon opac interface as a start point, within which the library web pages are an option.
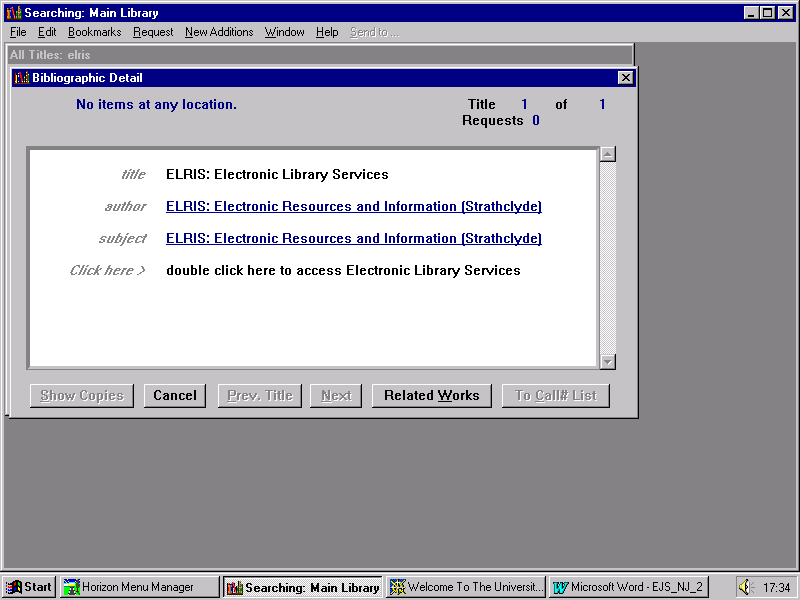
Figure 4. Strathclyde University Library opac screen.
One way of retrieving an e-journal record at the Andersonian is thus first to search the opac for a catalogue record which describes the appropriate electronic resource which will lead to an electronic journal. In this way, for example, a search for the "Electronic Library Services" item on the Strathclyde opac (Figure 4) brings up the appropriate web page (Figure 5) which will give the user e-journal access to a journal title via Netscape. Once the user has established access to the web browser via the opac, they can use the web pages e-journal links to browse the journal titles of their choice: the link "ejournals" on the "electronic information services" section of the "Electronic Library Services" acts as the next browse point in the process of retrieving the required e-journal title.

Figure 5. Strathclyde University Library web page.
Of course, the user does have the option of directly inputting an e-journal title at the opac screen, retrieving a catalogue record for that e-journal, and then clicking on a hyperlink in the catalogue record to access the title direct. However, as mentioned above, Strathclyde's statistics of use show that this is the retrieval method used in only 25% of e-journal interrogations - users would rather search for a very general "Electronic Library Services" web page from the opac and then browse to an e-journal title from the web starting point. The implication is that, outside the Library, where Netscape is the main search option on work stations rather than the Library opac, e-journal users bypass the opac entirely and simply browse to the e-journal web page of their choice via the Library's web-based title and subject listings.
An additional factor complicating the decision over whether to maintain dual access routes to e-journals has been the co-operative dimension. There has been increasing awareness in recent years of the need to develop library resources co-operatively on a regional basis. Two libraries a few miles apart in the West of Scotland which decide to develop in parallel two separate e-journal services need to keep this consideration carefully in mind. Most of the e-journal services used by Glasgow and Strathclyde University Libraries are common to both, so that there is clearly redundancy of effort in listing the same services. High levels of reciprocal access between the two libraries means increased pressure from users moving the short distance between the two institutions to create a common merged interface for virtual services such as e-journals which are equally accessible at both institutions and look the same used anywhere over the networks.
For each library to maintain four access routes to e-journals seems to add unnecessary layers of confusion to an overly complicated local situation - surely the need for transparent search tools between two neighbouring libraries would necessitate the pruning of this proliferation of e-journal listings?
To rationalise this proliferation, should both libraries concentrate on their opacs as their main source of e-journal information?
Each university uses a different library system (Ameritech-Horizon at Strathclyde, Innopac at Glasgow) and this places limits on the degree of co-operation that is possible when the ultimate aim in both cases might be a common interface, or failing that, two highly compatible or interchangeable interfaces for electronic networked services. For example, the Horizon system opac relies on a Windows-based client. The Horizon software supports hyper-links from the catalogue record to externals URLs, but the client-end of the software must be loaded separately on a user's pc, and for this a certain degree of local library systems support is necessary. There is a Horizon webpac, but it is not as highly developed as the Windows client opac, and, at the time of writing, it does not support hyper-links from the catalogue record to external web servers such as e-journal services. By contrast, the Innopac opac is entirely web-based, and part of its webpac functionality is to support hyper-links to external web servers.
Arguably, therefore, listings or catalogues of information services based on highly differentiated local library systems will not easily prove fertile ground for co-operation. The aim must be the pursuit of solutions which move us towards seamless, supra-institutional interfaces using proven information technologies, while we await the practical implementation of attempts to produce a Z39.50 solution to cross-opac searching between library systems, being developed over Scotland by the eLib 'clumps' project CAIRNS.6 However, those aspects of local library services that can now be separated out from local library systems and placed on a generalised web platform (such as certain library information services, among which e-journal services are one clear example) would be much more amenable to a co-operative approach, unhindered by diversities in local library system technology.
Indeed, a brief resume of the features in common between the two libraries' web e-journal listings appears to support this view - namely, broadly similar browsable sets of web pages, at the heart of which is an A-Z title listing, backed up by subject listings which mirror the shared research and teaching interests of both institutions. This is further underpinned by the recent decision at Strathclyde University Library to base its main web-based listing of all electronic library services (e-journals and bibliographic databases - (http://www.lib.strath.ac.uk/els) on the same web page design as the Glasgow University Library Databases and Datasets web page (http://www.lib.gla.ac.uk/Resources/Databases/index.html). Increasingly, students moving between both libraries should recognise a common feel to the information services at both sites.
Thus the need for local library collaboration seems to support at least the short term maintenance of parallel web and opac routes to e-journals, while any library which adopts a clear policy of listing e-journals solely in its own proprietorial opac would be cutting down its options for co-operation in collective listing projects, at least prior to Z39.50 functionality becoming a mainstream library opac implementation.
It is clear, then, that two libraries such as Glasgow and Strathclyde
University Libraries can tolerate and even justify a high degree of local
diversity in their electronic access tools, even with the ultimate aim of local
co-operation as an important background factor.
If this is true of local
library e-journal listings, is it also true of other e-journal access tools,
such as subscription agent services?
Broadly speaking, there is a strong argument for creating a "one-stop shop", a total e-journal aggregation service which can offer a single, magisterial overview of all online fulltext periodicals. This "gold standard" type of service has been described as:
"one standard way of accessing journal literature electronically…[and again] a single 'backbone' service across the site." 7 (p 169)
Unfortunately, most "total" solutions are not "total" enough - no aggregator service as yet includes all the e-journal providers that any one Library would wish to have covered by such an umbrella service.
Broadly speaking the perfect, all-inclusive e-journal aggregation service does not exist.
And there are many good reasons why a perfect aggregator is not realistically achievable.
For example, aggregators will often collocate journal titles to which there is no direct online access from your local institution with titles where there is such access. This juxtaposition of the available with the unavailable spreads as much confusion as it sheds light. This is a particular drawback when an aggregator buries e-journal tables of contents deep down in their web structure, where the user must browse through a forest of links, pages or forms before the elusive content page is found. Or worse, aggregator contents pages may be assembled dynamically by complex scripts which cannot be reproduced as a hyperlinked URL from an external web page or opac. Where possible, local library listings will hyperlink directly into an e-journal contents page, plucking it out of its confusing juxtaposition with unavailable e-journal titles and presenting it side by side with other locally available holdings. Interestingly, most, but not all, of the aggregators now enable this, with ingentaJournals the latest service to implement stable URLs, and allow direct hyperlinking. Where dynamic contents page creation makes this impossible, libraries can link to the home page of an external e-journal listing service, promoting it as a valuable source of e-journal information, but a partial one amidst a sea of other valuable, but partial e-journal lists.
The pursuit of the perfect aggregator has thus proved an illusory aim to date. However, as with "failure" to produce a single local library e-journal list, the lack of success in achieving this aim may be less problematic than first seems the case. It is true that hard-pressed libraries would like to rely on a single external aggregator service as their source of e-journal information, and the need to produce a local list in some shape or form (web, opac, or both) which points to a variety of external sources of fulltext e-journals is a burden. Should the perfect browsable and searchable, web-based, off the shelf umbrella service for e-journal information ever materialise, libraries would rejoice, and abandon their laborious local lists with alacrity.
However, diversity is the very essence of the modern internet, and while this poses problems, it is almost an inevitable by-product of the dynamism of the networks. Thus, it may be argued that users of networked information expect a dynamic proliferation of networked information services, and will, for example, move between a variety of networked sources of e-journal information with remarkable sophistication. The quest for a single aggregator service is thus unachievable, and it is to local library listing services that the e-journal user will have to look for some sort of overview of the situation. And even there a diversity of listings will need to be tolerated, in order to accommodate the variety of information retrieval tactics that are suited to a variety of users. Thus, a "one-stop shop" for e-journals exists neither within nor outwith the local library.
Our original article used the phrase "two perspectives" in describing the e-journal scene. Now we can say that the outlook has become more complex than envisaged even at that early stage in our respective e-journal implementations. The complexity of this situation is interesting to trace in print, but can be frustrating to work with in practice. In consequence of this, neither Glasgow nor Strathclyde can talk of their own respective institutional perspectives which they are trying to harmonise; rather both libraries are looking outwards simultaneously on an e-journal scene that is too diverse for them to address in terms of a rigid, single policy. This does amount to a workable approach, however - once diversity is accepted as a fact, not a problem, it can, in a sense, be made a strength by libraries adopting flexible and open policies which in turn lead to effective user-centred e-journal services.
Current developments are now leading beyond the argument in this article
concerning browsing and searching at the title level. Although this will remain
important, direct and immediate access to fulltext articles from current
awareness services and database searches is coming into focus (see for example a
recent article by Lorcan Dempsey and colleagues 8). Aggregators can sometimes
provide access from certain databases to certain journals e.g. the Ovid Biomed
Service linking from Medline to articles in their fulltext journal collections -
if you subscribe; BIDS ISI databases linking to ingentaJournals; FirstSearch
links to Electronic Collections Online; and HighWire links to and from PubMed.
The goal of transparent access from database to article, independent of
publisher or aggregator, is still some way off, if only because of competition
between aggregators. Developments however will undoubtedly continue: perhaps we
may be able to describe some real progress in this direction in another article
in two or three years' time.
1. Joint, N. et al., Implementing e-journal
access: two perspectives from Scotland, Serials, Vol. 10, no.2, pp 229-235, July
1997.
2. Woodward, H., Electronic journals - the librarian's viewpoint, Serials, Vol. 11, no.3, pp 231-235, November 1998.
3. Mabe, M., SuperJournal: the publisher's perspective, Serials, Vol. 11, no.2, pp 117-126, July 1998.
4. Tomney, H. & Burton, P.F., Electronic journals: a study of usage and attitudes among academics, Journal of Information Science, Vol 24, no.6, pp 419-429, 1998.
5. Bates, M.J., The design of browsing and berrypicking techniques for the online search interface, Online Review, Vol. 13, no.5, pp 407-424, 1989.
6. CAIRNS: Co-operative Academic Information Retrieval Network for Scotland. <http://cairns.lib.gla.ac.uk/>.
7. Turner, R., Full text services: the view of the agent, Serials, Vol. 11, no.2, pp 167-170, July 1998.
8. Dempsey, L., Russell, R. & Murray, R., A utopian place of criticism? Brokering access to network information, Journal of Documentation, Vol. 55, no.1, pp 33-70, January 1999.